There are many approaches to filter one table with another using Power Query. The most common solution I found was to join tables together, and then delete the resulting joined results. This feels like a poor solution, and reviewing Table.Contains, this seems like a good way to provide filtering without unneeded steps. After much research I finally understood the syntax for this. Table.SelectRows(Source, each Table.Contains(#"Grouped Rows",_,{"Key","Step"}))
A sample PBIX (Power BI Desktop File) is available on GitHub.
I've created a sample data set with the original data on the left, and the desired outcome on the right. The goal was to find the earliest Step for each Key, and presented the associated Val for that minimum row. Below is an example of the input data set on the left, and the desired outcome on the right.
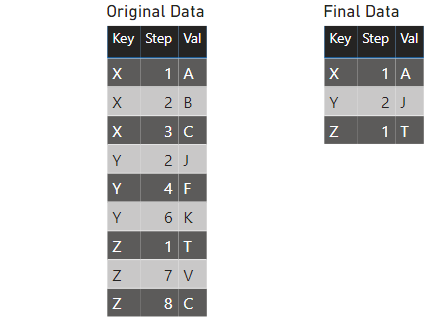
The Power Query code is broken into two separate tables, the Original Data table, and the resulting Final Data. I was able to copy and paste this code by clicking Edit Queries > Right clicking on the Final Result table in the left hand pane named Queries > and pasting it into a text editor.
The code for the original table is how the data is loaded.
Original Table
// Original
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WilDSUTIEYkelWB0IzwiIneA8YyB2BvMioXJecJ4JELvBeWZA7A3mRQFZ5kAcBudZwE2JgtoXohQbCwA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [Key = _t, Step = _t, Val = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Key", type text}, {"Step", Int64.Type}, {"Val", type text}})
in
#"Changed Type"
Final Table
// Final Result
let
Source = #"Original",
#"Grouped Rows" = Table.Group(Source, {"Key"}, {{"Step", each List.Min([Step]), type number}}),
#"Filter by Group" = Table.SelectRows(Source, each Table.Contains(#"Grouped Rows",_,{"Key","Step"}))
in
#"Filter by Group"
Filter by Group
#"Filter by Group" = Table.SelectRows(Source, each Table.Contains(#"Grouped Rows",_,{"Key","Step"}))
This provides the filtered data set described in the Final Data table. It references the Grouped step, but does not return from it. This step was created by editing directly in the Formula Bar as I don't believe there is a way to do this through the GUI.
We begin by defining our step, #"Filter by Group". Providing a clear simple name similar to generated code supports long term maintainability.If you find yourself unable to create a simple name due to complexity, consider breaking it out into multiple steps.
Table.SelectRows takes a table to be modified, and a compare function for each row. We reference Source, rather than #"Grouped Rows", as the resulting table. While inside the let, we can access previous steps by addressing their name with the #"" syntax. Table.Contains is our compare function, returning true or false based on the comparison done for each row.
For each row of the Grouped table, we compare it to the Record accessed by the each at the start of the second argument in SelectRows, which is addressed with _ as described in the Each documentation. This Record has the columns Step, Key, and Val avaiable to it. By default, it tries to make sure those columns, and only those columns, are matched in the Record of the Grouped by table we're on. This would fail as the Grouped Record only has Step and Key.
To match the two Records together when one has more columns than the other, we use a List of field names from the Grouped table to be found in the Source record, defined as {"Key","Step"}. This completes the inner and outer functions, with all the rows where there are a match returned as true and included in the resulting table of Selected Rows.
With this we have filtered a table with the result of another table based on matching rows without a join.
Why Table.Contains over Table.Join?
I believe this may be a better solution to filtering a table as the join comes with potential downsides that are avoided with this. If the two tables do not have the same granularity, such as one table having one record per value, and one table having multiple records per key, like the start and finish tables, joining those together would result in the table of 3 expanding to be a table of 9. If you do not want to include the results of the join, you also then need to delete the resulting column created that holds the values associated ot it.
It also means that the second table you've created can be stored as part of the expression creating a single table, instead of having a secondary table captured as an independent entity that is otherwise unused. This saves your model from some clutter, helpful in maintaining a long term solution as you get into hundreds of tables.
This pattern is also usable with any two tables that you wish to filter on, and the grouped by step was an example only for my own challenges. If you do wish to use it on another table that has different names, you will need to find a way to pass the Record in with the names matching, or identify a way to inform Power Query they are equivalent. This is another reason I preferred creating a solution inside a single let expression as managing the column names is simpler.
